
2nd Replication of Things Could Be Better
The third study, the second replication


I am on the cusp of receiving my PhD in psychology, and yet through all of my education I have never ran a real quantitative, data collecting study all on my own1. Feeling like this was a gaping hole in my resume, I decided to do one this year and I decided it would be a replication. I chose to replicate the study “Things Could Be Better” (now referred to as TCBB, because as a psychologist I am bound by tradition to turn everything I can into an acronym2).
In 2022 Adam Mastroianni and Ethan Ludwin-Peery published a study entitled “Things Could Be Better.” The study found that “when you ask people to imagine how things could be different, they imagine how things could be better.” In 2025 Violet Henriques published a replication of this study that found the same results. As far as I am aware, my study is the second replication of TCBB.
I chose to replicate TCBB because it sounded like it would be really easy to do so. This is called ‘publish or perish’. I chose to do it this year because I was teaching an Introduction to Psychology course and it sounded like it would be really easy to just make my students do all the data collecting. This is called ‘being the lead researcher’.
This is a real study and a real scientific paper. You can access all data and materials here. The citation for this project is:
Tubbs, J. (2026, May 7). Replication of Things Could Be Better [Preprint]. EdArXiv. https://doi.org/10.35542/osf.io/94bxm_v1
The Study
I used the replication as a learning device for my class. I broke the process into four separate assignments, and thus had the students working on it throughout the semester. The goal was to have the assignments guide students through the entire scientific process, from initial reading to data analysis.
Assignment 1: Students read the original “Things Could Be Better” article and wrote a summary of it. The goal was to ensure they understood the authors’ core questions, findings, and the concept of imagining ‘better’ as a default human response.
Assignment 2: Students read the replication of TCBB by VIolet Henriques. They then took the survey themselves and coded their own responses as ‘better’, ‘worse’, or ‘neutral’. They turned in a reflection on how knowing about the study’s finding might have biased their own answers. The goal was to familiarize them with the idea of replication as well as researcher bias.
Assignment 3: Students would administer a survey to 10 people using a specific 6-question battery. I personally chose the six questions that would appear on the survey that students would administer. The questions I chose were taken from both the original TCBB study and the Henriques replication, as well as some of my own inputs. The six questions were:
1) How could sleep be different?
2) How could pets be different?
3) How could your phone be different?
4) How could streaming services (e.g., Netflix, YouTube, Hulu, etc.) be different?
5) How could work be different?
6) How could society be different?
The students had to ask the questions to people and record their responses. I had each student evaluate on their own if a response was better/worse/neutral, and then turn in all their responses on a coding table. I also had them turn in a portion of participants’ full comments. The students also turned in a short reflection on what their experience was in administering the survey to people.
Assignment 4: I then took all of the responses and pooled them together into a single dataset. I did some basic statistics so that we knew what percentage of responses were better/worse/neutral, and summarized some of the common things students reported their participants saying about the questions. I also summarized the students reflections on the survey. I then gave all this compiled data back to the students so that they could write a final short paper on the overall experiment.
Results
First off, disclaimer: I used Gemini Pro to compile and summarize the data. I kept an eye on the math and saw no errors in how it added up the hard stats. I also skimmed through all the written responses, and the AI summaries of those all seem to match up. But I can’t guarantee perfect accuracy because, well, I didn’t manually go through and summarize everything myself. I chose not to do this because obviously I’m lazy3.
Let’s start with the final stats. Not all students turned in the assignment (sadly)4, so the numbers were not as high as the expected ideal. Nonetheless, in total there were 190 respondents with a total of 1140 responses. Each respondent gave an answer for each question, so there were no missing numbers in that regard. Nearly 76% of all responses were rated as better, about 9.5% were rated as worse, and about 14.5% were rated as neutral. For a complete breakdown of percentages on each individual question, click here. If you don’t want to click that link, I have included a bar chart for your viewing pleasure.
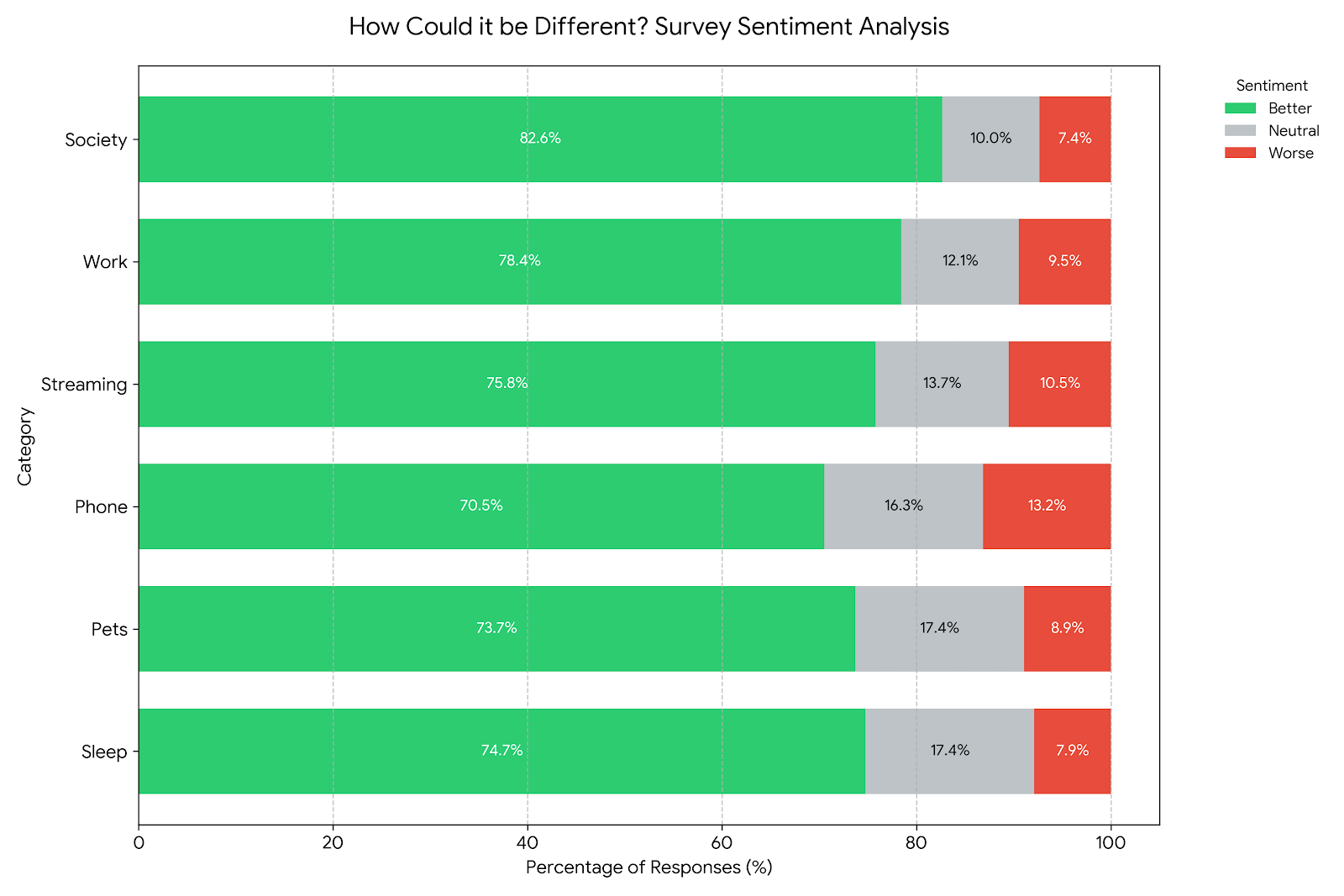
So, yeah, there it is. The majority of responses were better for every single question. Since they read through the original TCBB study and the replication, I don’t think any of my students were surprised by this.
Common Answer Categories
Since I had the students record the actual words people said, I was able to look at that data as well. I had a personal theory that most responses would fall into fairly few groups, and I think that was the case. I’ll just list some examples, you can look at the complete numbers here5.
For sleep, most better responses were about getting more sleep and feeling better (39 out of 68). Most better responses for phones were about longer battery life or screens that don’t crack (32 out of 63). Most better responses for streaming services were about them being cheaper and having no ads (39 out of 65). For work, the better responses were predictably about better pay and shorter hours (35 out of 60).
Disclaimer again: I also used Gemini Pro to group these answers/categories. Also, while we had 190 total participants, students were only required to turn in a portion of that for the verbatim responses6. So I only have responses from about 30 unique people at the most. Plus, responses to a single question often contained multiple categories. For example, one person said sleep could be better by having a more comfortable bed and sleeping eight hours. That’s one better response that can be grouped into two different categories. Finally, I only focused (or had AI focus) on better responses, because those were the most descriptive7.
Thoughts from Students
It’s pretty clear that this study supports the hypothesis that when asked how things could be different, most people most of the time respond with how things could be better. Granted, I didn’t do any fancy p-value statistics to see how significant this finding is, and 76% better is pretty different from the original TCBB’s 90% better. Why the difference? I don’t know, but one student hypothesized:
The original study had responses from 243 participants that were asked 52 questions. The replication had 190 participants that were asked 6 questions…The smaller pool of answers may have caused the results to not lean as hard toward better.
We were only about 50 participants shy of the original study, but had waaaay fewer questions. Perhaps if we had dozens of more questions then we would have had a higher percentage of better. Maybe next semester I’ll up question number and see what happens8. But I also want to point out that there was also a higher percentage of neutral responses than worse responses (neutral simply being anything that could not be categorized as better or worse). If we group the better and neutral together, then it reaches 90% of responses that were not worse. Maybe more significant than 76% of responses were better is that less than 10% of responses were worse.
Students reported that often the “simple” questions were harder to answer. People overthought the responses and took a long time (one participant took 30 minutes for the sleep question). Participants also wondered if they gave the “correct” responses; maybe they felt the better answers were in fact the right things to say. The society question was easily the most loaded question; students sometimes had to stop people from going into political or personal rants.
From a qualitative perspective, most students personally noted that it seemed easier for people to think of better answers than worse answers. When participants did think of worse options, sometimes it was with a “rebellious” or “bizarre” attitude (one person said having nuclear launch codes on a phone would be worse). Some students felt that personality and mood of the respondents drove a lot of the answers; positive people were more likely to think of improvements, stressed people gave more neutral/worse answers. So maybe the findings don’t so much look at people’s thoughts on phones or sleep as they look at general temperament and cultural background of the people asked.
When it came to coding, students sometimes didn’t know what to do. Sometimes a participant thought a change was better but a student felt like it was actually worse. Some responses defied the better/worse binary. The hardest response to code for one student was “only women work” for the work question; they had no idea if the participant meant that as a good or bad thing, and eventually they chose neutral because it would depend on the specific situation and/or person for this to be a better or worse difference. Multiple students said it would improve the study if participants coded their own responses instead of the students. I figure that’s a change I can make for future classes.
Personal Thoughts
I mentioned earlier that there tended to be more common answers for each question. My personal theory on this is it’s a matter of connection. When you ask someone how streaming services can be different, they don’t immediately think about how streaming services could also make you pancakes or cause an earthquake, because even though those things are different they are also pretty random. Most people will think about ads and cost, because after the service itself, those are two of the biggest aspects of a streaming service. Better would be no ads and cheaper cost, worse would be more ads and higher cost. But people jump to the better options before they jump to the worse options because everybody has at some point already thought, “geez, I sure wish I didn’t have to watch these ads”.
I suspect that the better option for a great many things has already been thought by people. “I wish my battery lasted longer”, “I wish I had gotten more sleep”, “I wish I got paid more.” I don’t think it’s that easy for every question though. Perhaps that’s why the society question was the most difficult to answer: though it could obviously be better, people are not confronted on a daily basis with a concrete example of how exactly it could be better.
Perhaps this is relevant to the mysterious Study 8 of the original TCBB; according to that, people could think of more ways things could be worse than better, even though they’re biased towards better. Maybe we can think of better things faster (since it’s already our default option), but since we’re only confronted with just a couple of specific ways things could be better on a daily basis, thinking beyond those defaults is tough. We’re not held back by habitual thought patterns for how things could be worse, so with a little imagination we can think of more possibilities9.
One major hole in this study that only a few students mentioned was demographics. I have no idea what the respondent demographics are10. Next time I could have students record demographic information for each respondent, but that’s more bookkeeping than I want them to do. This is a weakness of the study I’m not bothered enough by to fix. But someday I want to run a TCBB replication for Southeast Asia (specifically for Indonesia11) because I’m curious if their more collectivist cultural values would change the responses at all. But I know the original TCBB ran a trial for Chinese and got the same findings so I wouldn’t expect too much.
Finally, did my students learn anything from this? I hope so, but course evaluations haven’t been submitted yet so I can’t say with certainty. In all seriousness, I think they did. The students got to read real yet accessible scientific studies. They were familiarized with psychological concepts like biases. Class time was dedicated to learning about the scientific process and methodology, as well as the purpose of replications. And then they got to see how everything worked in a real study. Yes, I came up with the questions and compiled the stats, but they handled everything else, including analysis of what the data could mean. As far as class assignments go, it was better than some I’ve assigned.
And that’s it. What else is there to say except…
That’s replication, baby. 😎
References
Henriques, V. (2025, September 13). Two half-remembered replications. CounterfeitBees.
Mastroianni, A. M., & Ludwin-Peery, E. J. (2022). Things could be better. PsyArXiv. https://doi.org/10.31234/osf.io/2uxwk
Special thanks to my Spring 2026 Intro to Psychology class, without whom this project would have still been very much possible, but a whole lot more inconvenient.
I participated in one for a group project for an undergraduate class, but everyone knows those don’t count.
Technically it’s an initialism, because you pronounce each letter of TCBB instead of speaking it as a word.
Actually it’s because it would have taken forever. 1140 responses? Give me a break, I’m a one-man show here (plus 20 some odd students). I promise I’m not actually lazy, I just didn’t have time.
Yes, I have shared this write up with them, and yes, they know who they are.
Yes, in case you hadn’t realized yet, all of these hyperlinks lead to the same place.
Mainly because I didn’t feel the need to make them each write down 60 verbatim responses. It would have been a lot of extra work for them.
Allow me to restate this in proper academise: While the quantitative analysis tracked the frequency of the Better/Worse/Neutral codes across the full N=190 sample, the qualitative thematic analysis utilized an open-coding method. Because participants frequently provided multi-faceted responses, the thematic frequency counts reflect the total occurrences of ideas rather than a 1:1 participant-to-category ratio.
You better believe I’m going to replicate this study every single semester, though I’ll probably wait to publish on it again until I have a few runs over several semesters, then present them all as a single study program.
Maybe. I don’t know man, I’m just spitballing here.
One student did say that her 10 participants were all white males between the ages of 35-68, had all finished high school, and about 8 of them were farmers.
I speak Indonesian. Gotta play to your strengths.